Introduction
Portfolio optimization lies at the heart of asset management, guiding investment strategies from risk minimization to return maximization. Many of the most widely used allocation methods such as minimum variance, maximum Sharpe ratio, and risk parity rely on the inverse of the correlation matrix to compute optimal portfolio weights. However, if the correlation matrix is poorly conditioned (i.e., has a high condition number, which we will go into below), its inverse becomes highly sensitive to small changes in correlation estimates, leading to unstable portfolio allocations.
The problem arises because empirical correlation matrices, estimated from historical data, contain both true underlying structure and random sample noise. This noise can distort the eigenspectrum, leading to small eigenvalues that make inversion unstable. To mitigate this, we apply denoising techniques based on Random Matrix Theory (RMT) to improve stability. The goal is to reduce sensitivity in the inverse correlation matrix, making portfolio allocations more robust to estimation noise.
Correlation Matrix Inversion in Portfolio Optimization
The following table illustrates how the inverse correlation (or covariance) matrix appears in common asset allocation methods:
| Optimization Objective | Portfolio Weights Formula |
|---|---|
| Minimum-Variance Portfolio | |
| Mean-Variance (Markowitz) | |
| Maximum Sharpe Ratio | |
| Risk Parity | solve |
| Maximum Diversification | |
![\[w^* = \frac{\Sigma^{-1} \mathbf{1}}{\mathbf{1}^T \Sigma^{-1} \mathbf{1}}\]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-42f0945f6fd99399e8dd1fa2838b2933_l3.png "Rendered by QuickLaTeX.com")
![\[w^* = \lambda \Sigma^{-1} \mu\]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-19ab885243372cbc59bc51095d0bf6e2_l3.png "Rendered by QuickLaTeX.com")
![\[w^* = \frac{\Sigma^{-1} (\mu - r_f \mathbf{1})}{\mathbf{1}^T \Sigma^{-1} (\mu - r_f \mathbf{1})}\]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-35304f4f4c90f3153320d5c9ab881d02_l3.png "Rendered by QuickLaTeX.com")
![\[w_i (\Sigma w)_i = \frac{1}{N} \sum_j w_j (\Sigma w)_j\]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-50a44a63e5e2985946fd0a5ffed7d09a_l3.png "Rendered by QuickLaTeX.com")
![\[w^* = \frac{\Sigma^{-1} \sigma}{\mathbf{1}^T \Sigma^{-1} \sigma}\]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-27bd082297f24a8dd799383b7f006dd0_l3.png "Rendered by QuickLaTeX.com")
A correlation matrix can be viewed as a linear transformation that stretches or compresses a set of uncorrelated points into a correlated structure. The eigenvectors of the correlation matrix define the axes and the directions of this transformation, while the eigenvalues determine how much scaling occurs along each axis.
Visualizing Correlation and Its Inverse
Below, we illustrate this concept with three side-by-side scatter plots:
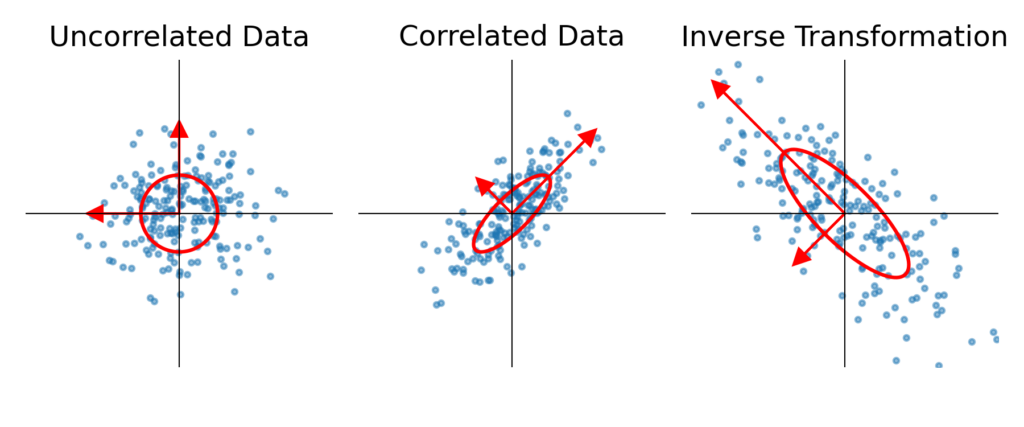
- Left: Uncorrelated data (standard normal distribution, spherical shape).
- Middle: Data transformed by a correlation matrix (stretched into an elliptical shape).
- Right: The effect of inverting the correlation matrix, illustrating how portfolio optimization weights are influenced.
The inverse transformation undoes this stretching/squashing process. If a correlation matrix has very small eigenvalues, these correspond to directions that are nearly collapsed, meaning their inverse will explode, leading to extreme allocations in the optimization process.
How Do the Vectors in the Inverse Transform Relate to Portfolio Weights?
The vectors plotted in the inverse transformation panel correspond to the principal directions of risk in the correlation matrix. These are the eigenvectors, and their associated eigenvalues determine how much the matrix stretches or contracts data in each direction.
Portfolio weights are most sensitive to:
- Small eigenvalues in
 , which become large when inverted.
, which become large when inverted. - Uncertainty in the direction of the eigenvectors, which determines how weight is distributed across assets.
If a correlation matrix has one very small eigenvalue, its inverse explodes, meaning any small change in correlation structure leads to a huge shift in portfolio weights. This is why a poorly conditioned correlation matrix leads to unstable allocations.
Uncertaintly in Correlation Estimates
In theory, we assume that the correlation matrix reflects true relationships between assets, but in practice, correlations are estimated from finite historical data and are subject to sample noise. Each correlation estimate is just an approximation of the true underlying structure, and these estimates fluctuate depending on the dataset used. The problem is twofold:
- estimated historical correlations are notoriously imprecise, the values you estimate are very noisy
- small variations in estimated correlations can -under certain conditions- significantly distort the portfolio weights, this happend when we have small eigenvalues and when the condition number is high
This issue becomes even more pronounced in large correlation matrices in a multi-asset setting, the more assets included, the higher the probability of encountering highly correlated noise events that introduce small eigenvalues. These spurious correlations arise purely due to randomness, yet they can significantly impact portfolio optimization by creating unstable inverse matrices.
In fig 2., in the left column -top to bottom-, we generated 3 samples of random data that was generated using the same true correlation of 0.8, yet the estimated correlation differs across samples, varying from 0.52 to 0.92. The key takeaway is that even when the true correlation structure is fixed, its empirical estimate varies due to sampling noise. This is a fundamental challenge in finance, where limited data availability makes robust correlation estimation difficult.

The right column shows the effect of inverting the noisy empirical correlation matrix. The inverse correlation matrix is highly unstable across different samples. This instability is caused by:
- Uncertainty in the estimated correlation matrix
- Since correlation estimates fluctuate due to sample noise, their eigenvectors also shift unpredictably, affecting the inverse.
- High correlation leading to small eigenvalues
- When assets are highly correlated, the correlation matrix has small eigenvalues, making inversion problematic.
- Small eigenvalues become large when inverted, leading to exploding elements in the inverse correlation matrix, which in turn makes portfolio optimization highly sensitive to small changes in correlation estimates.
This is why raw empirical correlation matrices often produce unstable portfolio allocations. Without regularization or denoising, small changes in historical data lead to drastically different asset weights, making any optimization unreliable.
Random Matrix Theory and the Marčenko-Pastur Distribution
When the number of assets is large compared to the number of observations, the empirical correlation matrix contains a significant amount of noise. The question then becomes: how do we distinguish true correlations from random noise?
This is where Random Matrix Theory (RMT) provides valuable insights. RMT studies the statistical properties of large random matrices. One of its key results is the Marčenko-Pastur distribution, which describes the expected distribution of eigenvalues when a correlation matrix is purely random -i.e., when the observed correlations contain no meaningful structure-.
The Marčenko-Pastur distribution describes the density of eigenvalues for a random covariance matrix constructed from independent Gaussian variables. The density function is given by:
![\[p(\lambda) = \frac{\sqrt{(\lambda_{+} - \lambda)(\lambda - \lambda_{-})}}{2\pi \sigma^2 q \lambda}\]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-2f52a5869cd925f84cccae6ced84cf81_l3.png "Rendered by QuickLaTeX.com")
where:
 represents the eigenvalues,
represents the eigenvalues, is the true variance of the underlying data,
is the true variance of the underlying data, is the aspect ratio (i.e., the number of time periods
is the aspect ratio (i.e., the number of time periods  divided by the number of assets
divided by the number of assets  ),
), and
and  are the theoretical lower and upper bounds of the eigenvalue spectrum, given by:
are the theoretical lower and upper bounds of the eigenvalue spectrum, given by:
![\[\lambda_{\pm} = \sigma^2 (1 \pm \sqrt{q})^2\]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-494770cd4177664c109f192d7931f722_l3.png "Rendered by QuickLaTeX.com")
This distribution serves as a benchmark for identifying noise in empirical correlation matrices: any eigenvalues inside the Marčenko-Pastur range are likely due to randomness, while eigenvalues outside this range may represent genuine structure.
To build intuition, we plot the Marčenko-Pastur distribution for different values of the aspect rati0  . This helps us see how the shape of the eigenvalue spectrum changes as we adjust the amount of data used to estimate correlations, or adjust the number of assets.
. This helps us see how the shape of the eigenvalue spectrum changes as we adjust the amount of data used to estimate correlations, or adjust the number of assets.
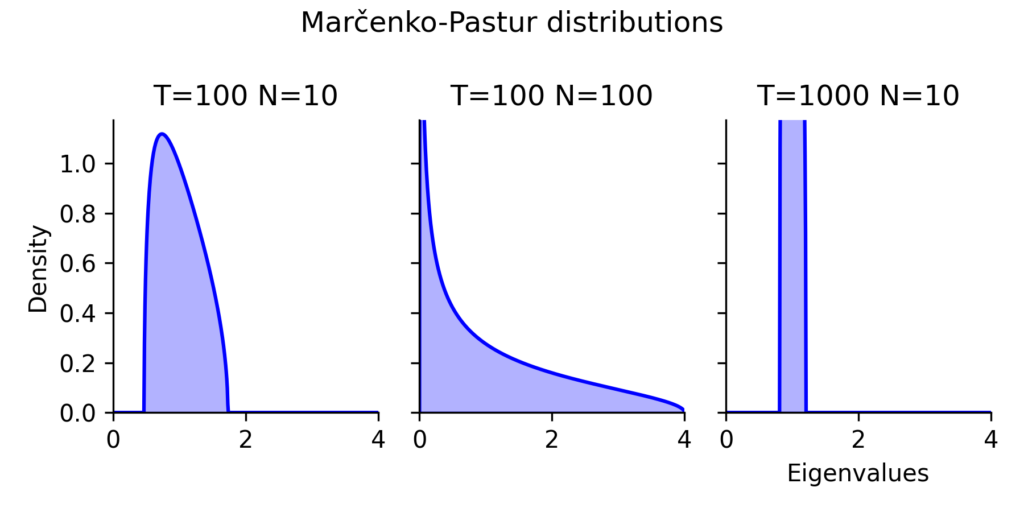
The three panels in (Fig 3) illustrate how the distribution of eigenvalues changes depending on the number of assets (N) and historical observations (T). The practical takeaway is clear: the ratio of historical data to assets strongly influences the stability of portfolio weights.
Left Panel: A somewhat typical case (T=100, N=10)
This represents a somewhat typical real-world scenario where we have more historical data than assets, but not by an overwhelming margin.
- The Marčenko-Pastur distribution tells us that any eigenvalue below ~1.8 is likely just noise.
- This means that many of the factors that appear significant in the correlation matrix are actually random fluctuations.
- The inverse correlation matrix will still be somewhat stable, but there is a risk of unstable portfolio allocations if the condition number is high.
Middle Panel: A Bad Situation (T=100, N=100)
This is a worst-case scenario where the number of historical observations matches the number of assets.
- The entire eigenvalue spectrum is stretched, meaning that even factors up to an eigenvalue of 4 are likely noise.
- The smallest eigenvalue is likely close to zero, meaning that inverting the correlation matrix will be extremely unstable.
- Portfolio optimizations in this setting will produce highly erratic weights that change drastically with small fluctuations in data.
This is a problem in high-dimensional finance, where investors want to include a large number of assets fro large universes but only have limited historical data. Without regularization, such matrices produce portfolio weights that are effectively meaningless.
Right Panel: A Well-Conditioned Case (T=1000, N=10)
This is the ideal scenario, where we have 100× more data than assets.
- The smallest eigenvalue due to noise is still likely around 1, meaning that all eigenvalues are well-separated from zero.
- This ensures that the correlation matrix inversion is stable, and portfolio weights remain robust.
- Even if correlations change slightly, the impact on portfolio allocations is minimal.
Denoising the Correlation Matrix to Stabilize Portfolio Weights
We’ve seen how sample noise in correlation estimates leads to small eigenvalues, which in turn cause instability when inverting the correlation matrix. Now, we introduce a denoising strategy that helps reduce this instability, making portfolio allocations more robust.
The key idea is simple: we need to separate true structure (signal) from random fluctuations (noise) and then modify the noise-dominated parts of the correlation matrix to improve its condition number.
Step 1: Estimating the Amount of Noise in the Correlation Matrix
The eigenvalues of a correlation matrix represent the variance explained by different factors. For an  correlation matrix, the sum of its eigenvalues is always equal to :
correlation matrix, the sum of its eigenvalues is always equal to :
![\[\sum_{i=1}^{N} \lambda_i = N\]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-135a5e3697e0f745e0a0fbebfcdebf84_l3.png "Rendered by QuickLaTeX.com")
This means that if there is real structure in the correlations, the signal-related eigenvalues will be larger, while the noise-related eigenvalues must be smaller to keep the sum constant.
To determine how much of the matrix is noise, we estimate the amount of variance explained by noise eigenvalues using maximum likelihood estimation (MLE). The idea is to fit the Marčenko-Pastur distribution to the empirical eigenvalues and estimate the variance of the random noise component. Any eigenvalue that is small enough to be explained by random noise is considered not meaningful.
At this stage, we have:
- A separation between “signal” and “noise” eigenvalues.
- An estimate of the noise level, which tells us how much distortion exists.
Step 2: Modifying the Smallest Eigenvalues to Reduce Instability
Once we identify the noise-dominated eigenvalues, the next step is modifying them to reduce their impact on portfolio weights.
Since the sum of eigenvalues must remain , simply increasing the smallest ones would require decreasing others, potentially distorting the true structure. Instead, a more stable approach is to replace all the noise-related eigenvalues with their average:
![\[\lambda_{\text{new}} = \frac{1}{K} \sum_{i \in \text{noise}} \lambda_i\]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-fc883952ada8131a85a3302374d837b6_l3.png "Rendered by QuickLaTeX.com")
where  is the number of noisy eigenvalues.
is the number of noisy eigenvalues.
This modification has several key benefits:
- It maximizes the smallest eigenvalue, improving the condition number.
- It maintains the total sum of eigenvalues, preserving the overall structure of the correlation matrix.
- It leaves the signal eigenvectors untouched, ensuring that meaningful correlations remain intact.
By applying this transformation, we stabilize the inverse correlation matrix, leading to portfolio weights that are far less sensitive to small changes in correlation estimates.
![\[ \Theta = (\alpha, \gamma, \beta, \text{var0}, \eta, \lambda) \]](https://www.sitmo.com/wp-content/ql-cache/quicklatex.com-5af1127950b35f71c5cccb10fe1376ff_l3.png "Rendered by QuickLaTeX.com")


 return distributions (pretrained pricing models)
return distributions (pretrained pricing models)